請到套件作者的下載頁面,下載版本對應的 ZIP 檔
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.9.0
點選 Extenstions
填入適當的資訊即可,這邊我都是用複製貼上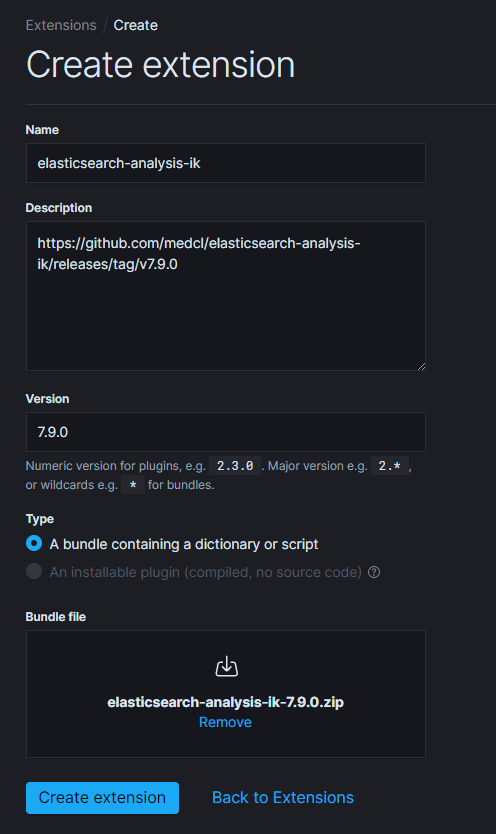
然後就安裝完成囉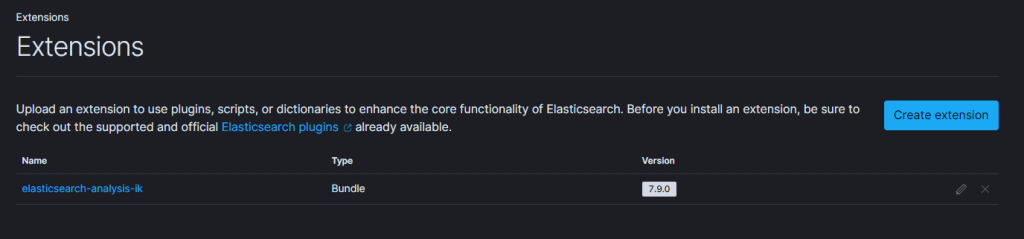
今天的操作是參考這一篇
安裝 ElasticSearch + Kibana 實現中文全文搜尋與數據分析
現在我還需要什麼呢? 詞庫。
畢竟如果後續要進行三國演義拆字,一個適當收錄人名的詞庫是需要。不過也許在此例中,讓我們簡化一點,就去網路上把主要的出場重要角色的人名當成詞庫就好。
那要如何確定今天的外掛安裝是正確的?
使用上文作者的示例,只是我蒐尋的詞更加具備普遍詞 "曾經";我們可以看到會出現 相關的字樣,可見此套件有完裝成功。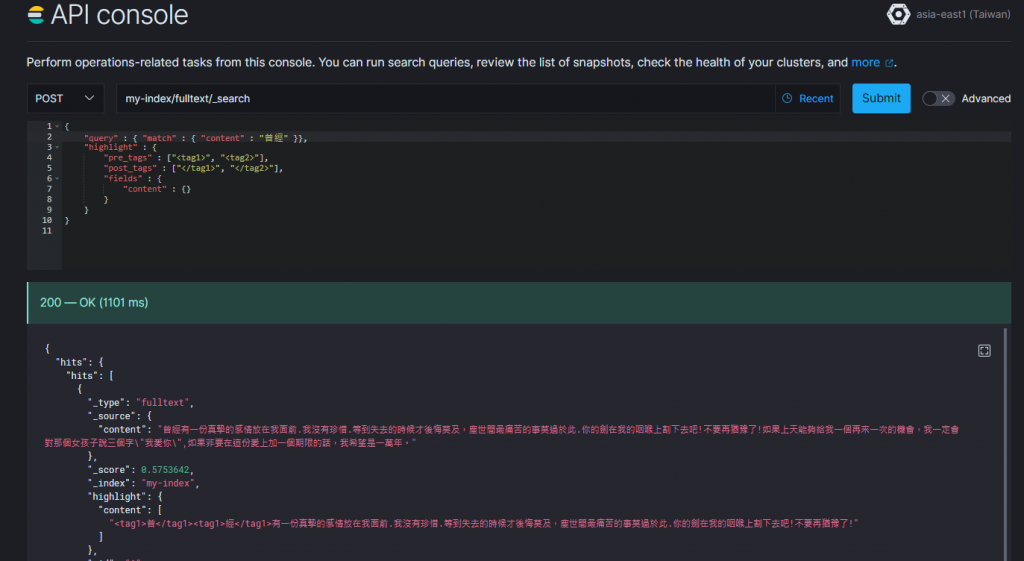
結論,NLP/Text Mining 不是我的專長,如果有任何錯誤,歡迎各位大大指正,謝謝。

